AI agents are no longer a future concern, they are running in your environment today, accessing production databases, calling external APIs, writing outputs to documents and collaboration platforms, and making decisions with little or no human review in between.
Most enterprises are not ready for them.
The governance and security frameworks built over the last decade. Identity management, access controls, data loss prevention, and compliance monitoring were all designed for a world of deterministic software and human users. AI agents are neither. They are different: they reason, they chain tools together, and they move data as a side effect of doing their jobs. The existing tools were never designed to watch them do it.
This is the first post in a four-part series from Trust3 AI on enterprise AI agent governance and security. The series is structured around a simple framework: Discover, Observe, Secure. This framework is built on the premise that you cannot govern what you cannot see, and you cannot secure what you have not mapped:
- Part 1 (this post): The problem — why existing governance and security models break for AI agent
- Part 2: Discover — how to build a continuous, automated AI agent inventory
- Part 3: Observe — what meaningful governance monitoring actually looks like
- Part 4: Secure — rethinking authorization for agents that reason and move data
This post starts with the problem. Before you can build the solution, you need to understand why the tools you already have are not sufficient – and what specifically about AI agents breaks the assumptions they were built on.
PART 1 — The Problem
Why AI Agents Break Every Governance and Security Model You Already Have
The enterprise AI security conversation today is centered on a few questions: what tools can the agent call? Which APIs can an agent invoke? Which databases can it query? Which Model Context Protocol (MCP) servers can it connect to? How does an agent communicate with another agent (A2A)?
These questions matter. They address only half the problem, but don’t address the dangerous half.
The harder question is what happens to regulated data after a model calls those tools. For example, an agent that has access to read customer PII from a production database and ends up exposing sensitive data via a processed summary to a shared document, a Slack channel, or an external API . In this scenario, it goes beyond what tools can the agents call that is the focus on many enterprises today. The data is moved, then transformed, and landed somewhere with different access controls, different retention policies, different regulatory exposure.
Agents are a unique class of software that routinely extracts, transforms, and deposits regulated data as a side effect of doing their job. Traditional data governance was designed for a world where data stays in place and people come to it. Agents have inverted that assumption entirely.
The industry is asking: what tools can models call? The right question is: what happens to regulated data after a model calls those tools?
Agents Are Not Just Interactive Chat Applications. They are Non-Human Identities doing actual work.
For a decade, enterprise AI governance meant model governance – bias testing, accuracy monitoring, fairness audits. This is important work, but it assumes AI is a tool a human picks up, uses, and puts down.
Agents change that assumption in three fundamental ways.
Autonomy. An agent receives a goal, decomposes it into sub-tasks, selects tools, and executes actions across dozens of API calls in a single session. The human sets the goal at the start and sees the result at the end. What happened in between is the governance gap.
Persistence. Agents maintain context, build memory, and in many enterprise deployments run on schedules with no human oversight. An analytics agent runs every morning against your data platform with any human intervention (prompt). It has a job and does it continuously.
Data movement. This is the critical distinction. Agents don’t just answer questions about data – they extract it, reason across it, transform it, and deposit the results elsewhere. In Databricks, an agent runs under a service principal with Unity Catalog permissions. It reads regulated tables, processes their contents, and writes outputs to files, documents, emails, downstream APIs, and other agents’ context windows. Each deposit is a data governance event that no existing tool is watching.
Every AI agent, in practice, is a non-human identity with autonomous access to enterprise data and autonomous ability to move it. Most organizations have some governance framework for how agents can inherit human or machine identities. What these identities can do with data is not on the radar of many organizations.
| Why Existing Security tools such as Identity and Access Management (IAM) Breaks |
| IAM governs authentication and static permission grants. |
| It has no model for data movement — what an agent does with data after accessing it, or where that data goes. |
| An agent can be fully authorized under IAM while extracting regulated data and depositing it in a dozen unmonitored destinations. |
| IAM answers: can this identity access this resource? It cannot answer: after accessing it, where did the data go? |
The Access Chain Nobody Is Watching: The Dilemma of a Broken Chain
The need to follow a single agent interaction end to end: Identity → Agent → Tool → Data.
Your security team manages identities. Your data team manages data. Your platform teams manage infrastructure. Nobody owns the chain. And critically, nobody is watching what happens after the agent reaches the data — the reverse chain that flows back out: Data → Agent context → Tool output → Destination.
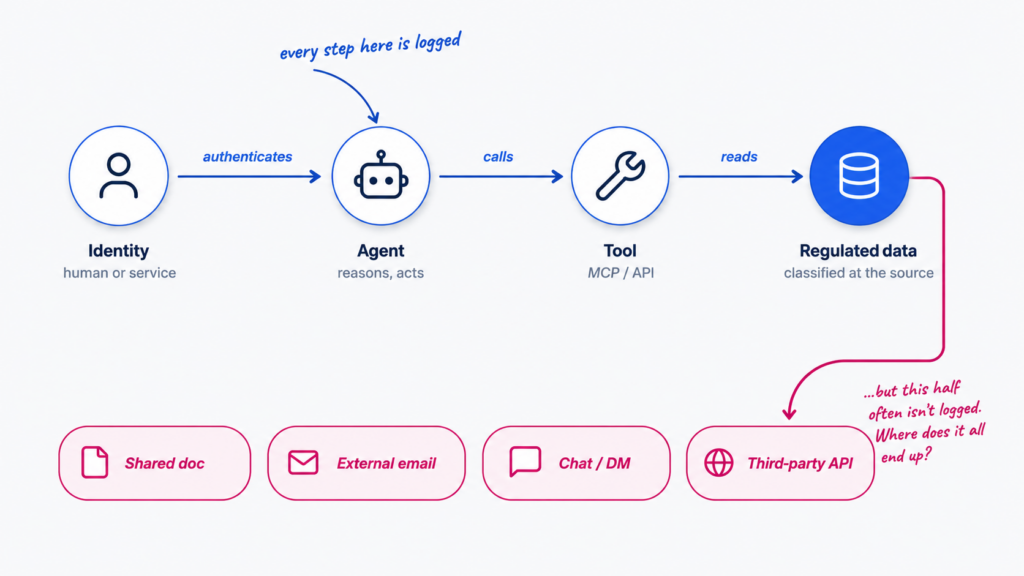
Traditional tools each see a piece of the inbound chain. None of them see the outbound chain at all. The agent extracts, the context window becomes a data carrier, and regulated content spreads across destinations that were never reviewed, never classified, never governed.
The Comparison: Traditional IAM vs. AI Agent Reality
| Traditional IAM | AI Agent Reality | |
| Identity type | Human users + service accounts | Autonomous non-human agents |
| Behavior model | Static, deterministic | Dynamic, probabilistic, reasoning-driven |
| Permission model | Explicitly granted | Inherited, accumulated, chain-amplified |
| Authorization unit | User action on resource | Agent intent across tool chain |
| Data movement | Static — data stays at source | Dynamic — agent extracts, transforms, deposits |
| What it governs | Authentication + access rights | Not behavioral scope, not data flow, not destination |
| Audit trail | Access events | Access events only — no data provenance |
Why Reasoning Breaks the Authorization Model
Traditional access control resolves a binary question: does this identity have permission to perform this action on this resource? This model works in traditional data environments because it was designed for deterministic entities. A service account queries certain tables and nothing else. The permission set is a complete specification of what the entity can and should do.
AI agents violate that assumption at the foundation. An agent doesn’t execute a fixed workflow. It reasons toward a goal, and the path it takes through its available tools is determined at runtime by the model.
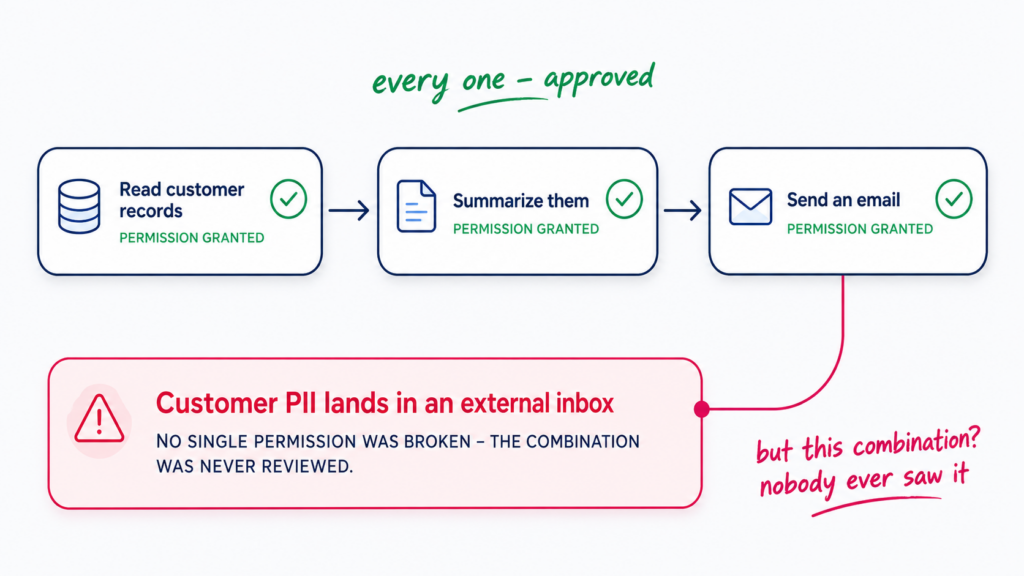
Consider an agent authorized to query customer records, summarize documents, and send emails. Each permission looks reasonable on its own. Now consider what the agent can accomplish by chaining those three permissions together: retrieve customer records, summarize them, email the summary to an external address. No individual action violates permissions. However, the combination of this achieves something that was never authorized. – In which the agent can reason and execute without being explicitly instructed – . And the regulated data from those customer records is now in an external inbox.
An agent can construct multi-step action sequences that combine individually permitted actions in ways that no authorization review ever evaluated. The chain was never authorized. And the data moved.
MCP Servers and the Blast Radius Problem
This problem compounds dramatically as agents connect to more tools through the Model Context Protocol (MCP).
MCP is the emerging standard for connecting AI agents to external capabilities: databases, file systems, email servers, code execution environments, calendars, CRM systems, internal APIs. Each connection expands both what the agent can access and where it can deposit data.
Consider an agent connected to five MCP servers: a database server with access to customer records, a file system server with read and write permissions, an email server, a code execution server, and a calendar server. Each individual connection looks justifiable. However, the combination doesn’t.
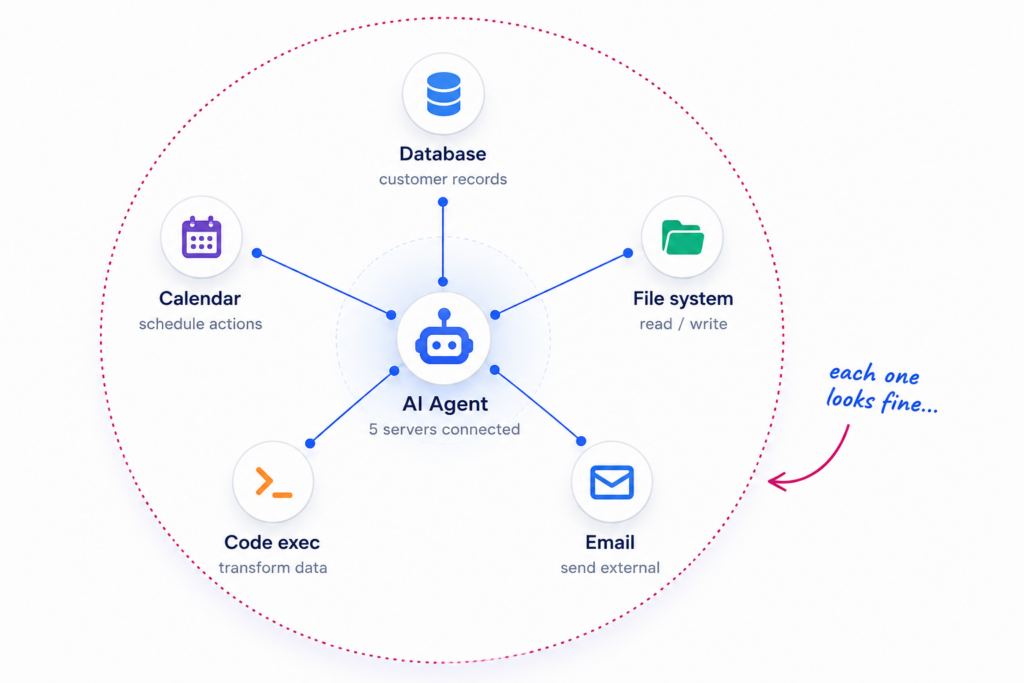
That agent can read sensitive customer records, write them to files, email those files to external addresses, execute code to transform the data before exfiltration, and schedule follow-up actions autonomously. None of these individual actions is technically blocked. But the data has traveled from a governed, classified source through an ungoverned chain to an uncontrolled destination. The blast radius is not just what the agent can access, but also what it can do to data after it accesses it.
The blast radius of a compromised or drifting agent is not just the data it can access. It is what it can accomplish by chaining connected tools, and where it can spread regulated data.
Four Failure Modes Already Happening
These patterns appear consistently when organizations start auditing their agent estates.
The over-permissioned agent. A marketing analytics agent is configured against a set of tables in the data platform, where one contains PII. A governance policy says marketing systems must not process PII directly. That policy was never associated with the agent’s service account during provisioning. The agent runs for months and no alert surfaces. This is a typical case where the policy existed in a document, while the violation exists in production.
The drifting agent. A financial services firm deploys an agent designed to work only with loan origination data. However, in practice, users can get answers to almost anything: HR policy questions, competitor summaries, and other queries well beyond its approved scope. This creates a serious problem in a regulated setting. When a system operates outside its defined governance boundary, its outputs cannot be tied back to an audited, approved process, and that undermines both compliance and accountability.
The shadow agent. A data engineering team builds a LangChain agent that connects to the analytics warehouse using a personal developer credential. That credential never shows up in security audit logs, security never reviews it, and it appears in no inventory. When the engineer later moves to a different role, no one rotates the credential. As a result, the agent keeps running with genuine access to real data, yet there is no oversight trail to track what it does. This leaves the organization exposed to serious security and governance risks, with active access that no one owns, monitors, or controls.
The data-spreading agent. A supply chain analyst at a retail company deploys a Databricks agent to summarize supplier performance. The agent is authorized to read supplier contracts, payment history, and performance metrics — all internal, none individually classified as regulated at the source. In the course of answering a question about Q3 performance, the agent reads contract terms containing proprietary pricing agreements, synthesizes them into a summary, and writes that summary to a Confluence page shared with a vendor partner. Three tool calls, each individually authorized, raised no concerns on their own. Together, however, they formed a chain that moved confidential pricing data from a governed internal database into a vendor-accessible document. No DLP rule was fired. No access policy was violated. The agent did exactly what it was authorized to do. The problem is that nobody governed where the data went.
These four patterns share a root cause: there is no system that knows the full inventory of agents running in the enterprise, what data each one is accessing and moving, and whether the destinations that data reaches are appropriate for its source classification.
| What CISOs and CIOs Should Ask |
| How many AI agents are currently running on our infrastructure? Is this number from a system or from a survey? |
| For each agent: what is the full set of MCP servers and tools it is connected to? Has anyone evaluated the data movement surface that combination creates? |
| When our agents access regulated data, where does that data go afterward? What destinations — documents, emails, APIs, other agents — does it reach? |
| If a specific agent accessed customer PII and wrote a processed output to an external-facing destination, how long would it take us to know? Do we even have the instrumentation to detect it? |
The Regulatory Dimension
Regulatory frameworks are catching up to autonomous AI systems, even as specific timelines shift.
The EU AI Act establishes risk classification and documentation obligations. GDPR and CCPA are already in force and already apply to data processed by AI agents. Both require knowing not just what personal data you collect, but where it is stored and who can access it. An agent that reads PII and writes a processed output to five different destinations has created five new data residency concerns that didn’t exist before the agent ran. Whether those concerns constitute a compliance event depends on the destinations — and most organizations today have no visibility into where agent-processed data lands.
HIPAA-covered entities face the same exposure. PHI that enters an agent context and propagates to non-covered-entity destinations is a breach scenario regardless of whether the agent’s original data access was authorized.
Three Questions. One Framework.
What agents do we have, what can they reach,and move? Not just identity and permissions. The full connected tool surface and the potential data movement pathway that surface creates.
What are they actually doing with data, not just accessing? The gap between declared purpose and actual behavior includes scope drift and policy violations. But it also includes the output side: what did the agent produce, where did it go, and does that destination match the classification of the source?
Can we enforce policy on both access and data flow? Knowing a violation occurred is not the same as preventing it. Enforcement requires policy at the access layer and policy at the data flow layer — governing both what agents can read and what they can do with data after reading it.
Discover every agent. Observe every action. Secure every interaction — including what happens to data after the interaction ends.
What This Means and What Comes Next
The patterns described in this post are not theoretical. They are active in enterprise environments right now. Agents are running without inventory, accessing data beyond their declared scope, producing outputs that land in destinations nobody reviewed. The governance tools most organizations rely on were not built for this, and the gaps are structural, not incremental.
The good news: the problem is solvable. The architectural foundation for governing AI agents, connecting data classification at the platform layer to agent behavior to destination enforcement, already exists in most enterprises in pieces. The work is assembly: building the layer that connects what agents can access, to what they actually do with data, to where that data ends up.
That work follows the Discover → Observe → Secure framework, and it has to start with discovery. You cannot write a policy for an agent you don’t know exists. You cannot monitor behavior you haven’t mapped. You cannot calculate data movement exposure for a system that isn’t in your inventory.
Part 2 of this series tackles discovery head-on: why manual agent registration fails at scale, where agents actually live in your infrastructure, and what a continuous, automated agent inventory needs to look like in practice. The honest answer in most enterprises today is that no one knows exactly how many agents are running or what they can reach. Part 2 is about changing that.
| NEXT UP: PART 2 — DISCOVER You Can’t Govern What You Can’t See: Building a Continuous AI Agent Inventory Ask a CISO how many AI agents are running in their environment. The most common answer isn’t a number — it’s a pause. Part 2 explains why manual registration fails at scale, where agents actually live in your cloud infrastructure, and what it takes to build an agent inventory that keeps pace with how fast AI is being deployed. |