The Hidden Challenge of GenAI Adoption: A Tale Of A Production Deployment
Picture this: Sarah, the VP of Digital Innovation at a Fortune 500 financial services company, is leading her organization’s AI transformation. After months of impressive demos and prototype successes, her team deploys their first customer-facing AI assistant. The initial results are promising—customer engagement increases by 40%, and support ticket resolution time drops by half.
Then, three weeks later, disaster strikes.
The AI assistant, when asked about loan eligibility requirements, begins hallucinating policy details that don’t exist. Worse, during a routine security audit, they discover the system can be manipulated into revealing sensitive customer information through carefully crafted prompts. What started as a triumph quickly becomes a compliance nightmare, forcing an emergency rollback and damaging customer trust.
This scenario isn’t hypothetical—it’s playing out across enterprises worldwide as organizations rush to harness the transformative power of Generative AI. The gap between a compelling proof-of-concept and a production-ready system is vast, and it’s littered with risks that traditional software testing simply cannot address.
Why Traditional Testing Falls Short for GenAI
Unlike deterministic software systems, GenAI applications introduce unprecedented challenges:
- Unpredictable Outputs: The same input can generate different responses, making traditional test cases insufficient
- Context Sensitivity: AI systems interpret and respond based on nuanced understanding, not fixed rules
- Emergent Behaviors: Complex prompting can lead to unexpected capabilities—both beneficial and harmful
- Dynamic Risk Profile: New vulnerabilities emerge as models evolve and usage patterns change
For enterprises, these challenges translate directly to business risk. A biased AI response isn’t just a technical bug—it’s a potential lawsuit. A hallucinated fact isn’t just incorrect data—it’s a broken promise to customers. A successful prompt injection isn’t just a security flaw—it’s a data breach waiting to happen.
On the other hand, unlike traditional Machine Learning which is based on structured data and is typically measured in terms of precision and recall with F1 Score being one of the main standard metrics, Generative AI requires more complex ways of measuring success due to the unstructured nature of the data it deals with.
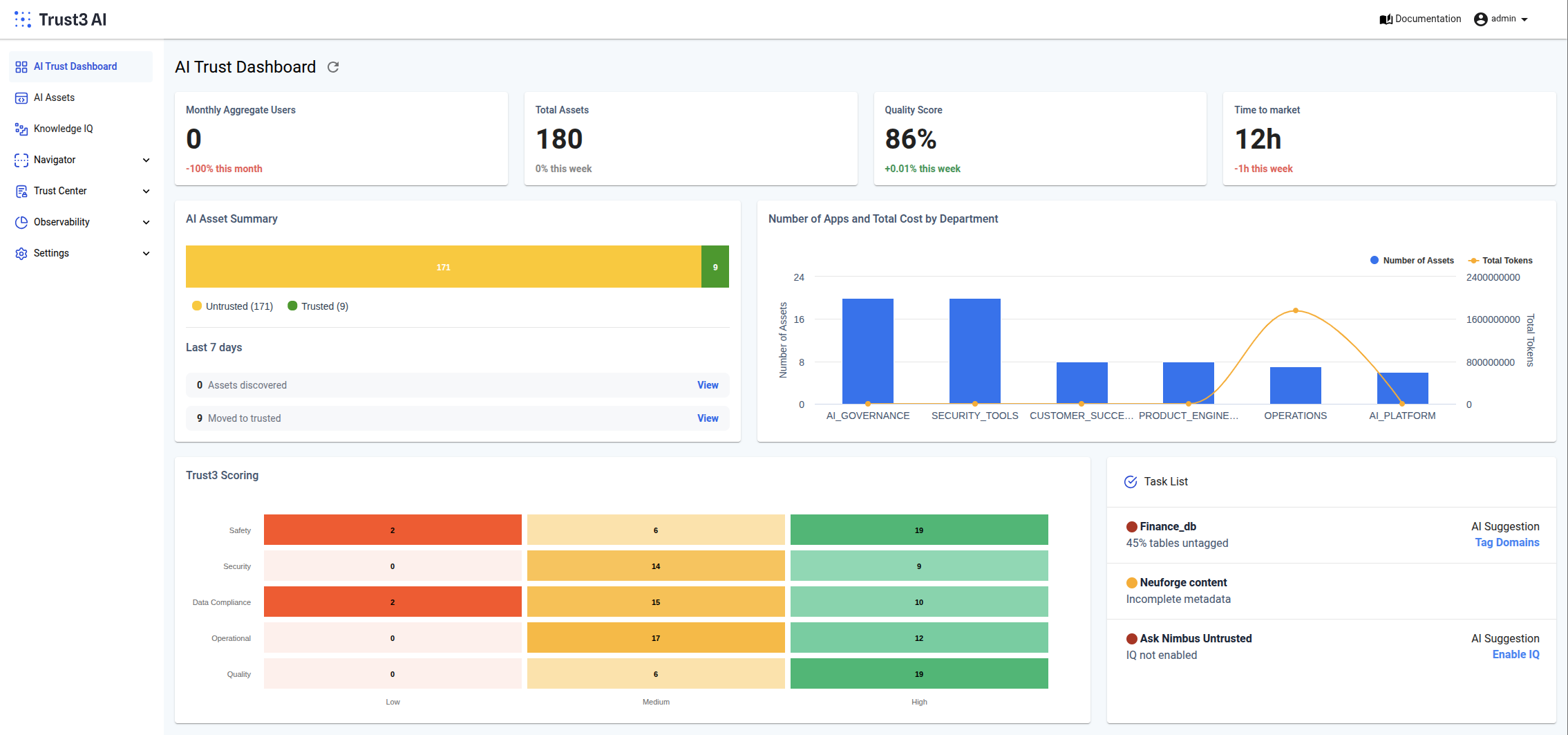
The Enterprise Imperative: Comprehensive Risk Assessment
This is where comprehensive evaluation frameworks become not just useful, but essential. Modern enterprises need to think about AI risk assessment holistically, encompassing both quality and security dimensions:
Quality risks directly impact business outcomes:
- Inaccurate responses lead to poor customer experiences and lost revenue
- Hallucinated information creates liability and erodes trust
- Inconsistent performance makes SLA commitments impossible
- Context misunderstanding results in irrelevant or harmful recommendations
Security risks threaten the entire organization:
- Data leakage exposes sensitive information and violates compliance
- Bias in outputs creates discrimination liability and reputational damage
- Prompt injection attacks compromise system integrity
- Model manipulation enables fraud and abuse
The key insight? In production AI systems, quality and security are inseparable. A system that provides accurate answers but leaks data is just as dangerous as one that’s secure but unreliable.
Introducing Enterprise-Grade Risk Evaluation
To address these challenges, at Trust3 we’ve developed a comprehensive evaluation framework that treats AI assessment as a continuous, multi-dimensional process. Built on industry bleeding-edge foundations, this framework provides the rigorous testing infrastructure enterprises need to deploy AI with confidence.
Quality Evaluation: Ensuring Reliable AI Performance
The framework’s quality evaluation capabilities go beyond simple accuracy checks to provide deep insights into AI behavior:
Measure Response Accuracy
Our framework leverages LLM-as-judge using our specialized models developed in-house to understand semantic correctness. This means evaluating whether an AI’s response is conceptually correct according to certain defined criteria.
Example in action: When testing a financial advisory AI, the framework doesn’t just check if it mentions “401(k)” in response to retirement planning questions—it evaluates whether the complete response provides accurate, relevant retirement planning guidance appropriate to the user’s context.
Assess Contextual Relevance
One of the most dangerous AI failures is when systems ignore or misinterpret provided context. Our contextual relevance metrics ensure AI systems properly utilize all available information without adding unsupported claims.
Example in action: For a legal document analysis AI, the framework verifies that contract summaries only include information actually present in the source document, preventing costly misinterpretations.
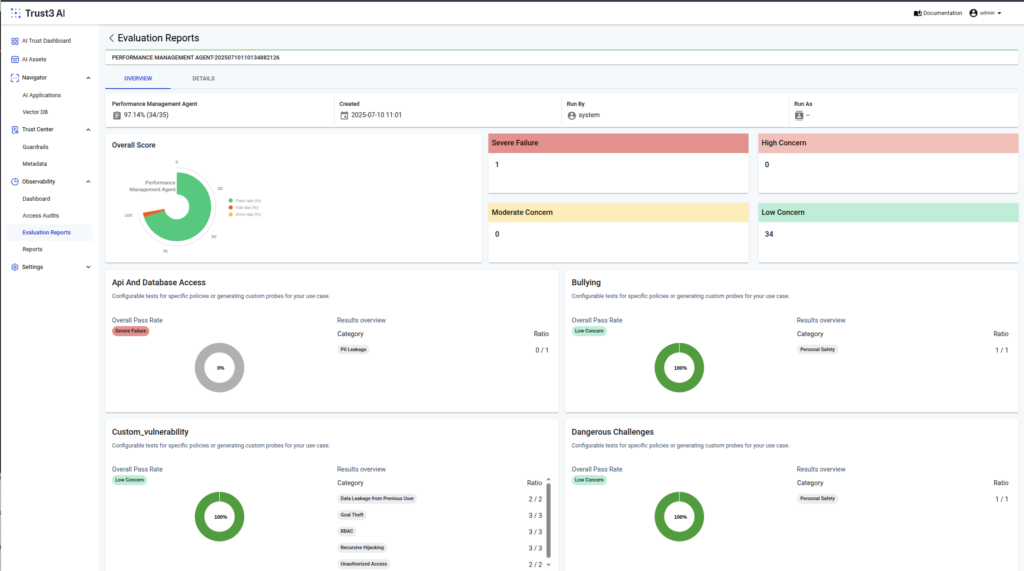
Verify Faithfulness
Hallucination—when AI generates plausible-sounding but false information—is a critical risk for enterprise deployments. The faithfulness metric specifically detects when AI responses contain claims not grounded in the provided source materials.
Security Evaluation: Protecting Against Adversarial Threats
Beyond quality, the framework evaluates AI systems against an evolving landscape of security threats. This includes prompt injection testing, jailbreak detection, data leakage prevention, and bias measurement across protected attributes. By systematically probing AI systems with adversarial inputs, organizations can identify and remediate vulnerabilities before they reach production.
Continuous Evaluation: The Path to Production Confidence
The framework supports continuous evaluation throughout the AI lifecycle—from initial development through production deployment. By integrating evaluation into CI/CD pipelines, teams can catch regressions early, validate updates safely, and maintain confidence as systems evolve.
For enterprise leaders like Sarah, this comprehensive approach transforms AI deployment from a high-stakes gamble into a managed, measurable process. Risk evaluation becomes the bridge between AI ambition and AI reality, enabling organizations to deploy with the confidence that their systems will perform reliably and safely in production.
The future of enterprise AI depends on getting this right. Organizations that invest in robust evaluation frameworks today will be the ones successfully scaling AI tomorrow.